

Model Onboarding#
Use this notebook for the exposure initial upload and risk dataset creation of a set of factor exposures using daily CSV files.
The notebook contains a section that obtains coverage statistics of the created risk dataset against the uploaded exposures.
import datetime as dt
import itertools as it
import shutil
import tempfile
from pathlib import Path
import polars as pl
from tqdm import tqdm
from bayesline.apiclient import BayeslineApiClient
from bayesline.api.equity import (
CategoricalExposureGroupSettings,
ContinuousExposureGroupSettings,
ExposureSettings,
DerivedRiskDatasetSettings,
RiskDatasetReferencedExposureSettings,
RiskDatasetUploadedExposureSettings,
UniverseSettings,
)
bln = BayeslineApiClient.new_client(
endpoint="https://[ENDPOINT]",
api_key="[API-KEY]",
)
Exposure Upload#
exposure_dir = Path("/PATH/TO/EXPOSURES")
assert exposure_dir.exists()
exposure_dataset_name = "My-Exposures"
Below creates a new exposure uploader for the chosen dataset name My-Exposures. See the Uploaders Tutorial for a deep dive into the Uploaders API.
exposure_uploader = bln.equity.uploaders.get_data_type("exposures")
uploader = exposure_uploader.create_or_replace_dataset(exposure_dataset_name)
# list all csv files and group them by year
# expects file pattern "*_YYYY-MM-DD.csv"
all_files = sorted(exposure_dir.glob("*.csv"))
existing_files = uploader.get_staging_results().keys()
files_by_year = {
k: list(v)
for k, v in
it.groupby(all_files, lambda x: int(x.name.split("_")[1].split(".")[0].split("-")[0]))
}
files_by_year.keys()
print(f"Found {len(all_files)} files.")
print("Years:", ", ".join(map(str, files_by_year)))
Found 31 files.
Years: 2025
Below we batch the daily CSV files into annual Parquet files. Creating batched Parquet files is recommended as it will be much faster to upload and process compared to individually uploading daily files.
temp_dir = Path(tempfile.mkdtemp())
print(f"Created temp directory: {temp_dir}")
Created temp directory: /tmp/tmpdqjj1m6k
for year, files in tqdm(files_by_year.items()):
parquet_path = temp_dir / f"exposures_{year}.parquet"
df = pl.scan_csv(files, try_parse_dates=True)
df.sink_parquet(parquet_path)
df.head().collect()
| date | asset_id | market^Market | style^Size | style^Value | style^Growth | style^Volatility | style^Momentum | style^Dividend | style^Leverage | asset_id_type |
|---|---|---|---|---|---|---|---|---|---|---|
| date | str | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | str |
| 2025-05-01 | "IC000B1557" | 1.0 | 0.470459 | 1.3535156 | -0.217041 | -0.161893 | 0.6529541 | 0.066101 | 0.4144516 | "bayesid" |
| 2025-05-01 | "IC0010CEFE" | 1.0 | -1.489746 | -0.119995 | -0.66748 | 2.1402996 | -0.570312 | 0.029068 | -0.318726 | "bayesid" |
| 2025-05-01 | "IC0021AFB7" | 1.0 | -0.437744 | -0.035828 | -0.196411 | -0.998698 | 0.69751 | 0.221924 | -0.07859 | "bayesid" |
| 2025-05-01 | "IC002CE8B9" | 1.0 | 0.147491 | 0.7685547 | -0.57666 | 1.3333334 | -0.302246 | 0.21106 | 0.202637 | "bayesid" |
| 2025-05-01 | "IC002DC646" | 1.0 | 0.188354 | 0.014297 | 0.083984 | -0.636719 | -0.506348 | 0.33667 | 0.064331 | "bayesid" |
As a next step we iterate over the annual Parquet files and stage them in the uploader. See the Uploaders Tutorial for more details on the staging and commit concepts.
for year in files_by_year.keys():
parquet = temp_dir / f"exposures_{year}.parquet"
result = uploader.stage_file(parquet)
assert result.success
shutil.rmtree(temp_dir)
Data Commit#
Next up we commit the data into versioned storage.
uploader.commit(mode="append")
UploadCommitResult(version=1, committed_names=['exposures_2025'])
Risk Dataset Creation#
Below creates a new Risk Dataset using above uploaded exposures. See the Risk Datasets Tutorial for a deep dive into the Risk Datasets API.
risk_datasets = bln.equity.riskdatasets
# exisint datasets which can be used as reference datasets
risk_datasets.get_dataset_names()
{'bayesline/Bayesline-US-500-1y': 'ready',
'bayesline/Bayesline-US-All-1y': 'ready'}
risk_dataset_name = "My-Risk-Dataset"
risk_datasets.delete_dataset_if_exists(risk_dataset_name)
We need to specify an assignment of which exposures are style, region, etc. Below lists those factor groups as they were extracted from the uploaded exposures.
uploader.get_data(columns=["factor_group"], unique=True).collect()
| factor_group |
|---|
| str |
| "market" |
| "style" |
See API docs for DerivedRiskDatasetSettings and RiskDatasetUploadedExposureSettings for other potential settings.
In this recipe we pass through the industry hierarchy from the reference risk dataset, choose that our uploaded exposures make up the estimation universe and that we take the union of all assets across all of our exposures as the overall asset filter.
settings = DerivedRiskDatasetSettings(
reference_dataset="bayesline/Bayesline-US-All-1y",
exposures=[
RiskDatasetReferencedExposureSettings(
categorical_factor_groups=["trbc"],
continuous_factor_groups=[],
),
RiskDatasetUploadedExposureSettings(
exposure_source=exposure_dataset_name,
continuous_factor_groups=["market", "style"],
categorical_factor_groups=[],
),
],
trim_start_date=dt.date(2025, 5, 1),
trim_assets="asset_union",
)
exposures_api = bln.equity.exposures.load(
ExposureSettings(
exposures=[
ContinuousExposureGroupSettings(hierarchy="market"),
ContinuousExposureGroupSettings(hierarchy="style", standardize_method="equal_weighted"),
CategoricalExposureGroupSettings(hierarchy="trbc"),
],
).with_dataset("bayesline/Bayesline-US-All-1y")
)
exposures_api.get(
UniverseSettings(),
standardize_universe=None
)
| date | bayesid | market.Market | style.Size | style.Value | style.Growth | style.Volatility | style.Momentum | style.Dividend | style.Leverage | trbc.Energy | trbc.Basic Materials | trbc.Industrials | trbc.Consumer Cyclicals | trbc.Consumer Non-Cyclicals | trbc.Financials | trbc.Healthcare | trbc.Technology | trbc.Utilities | trbc.Real Estate | trbc.Institutions, Associations & Organizations | trbc.Government Activity | trbc.Academic & Educational Services |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | str | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 |
| 2025-03-31 | "IC000B1557" | 1.0 | 0.4478 | 1.698971 | 0.089872 | -0.039851 | 0.800677 | 0.28382 | 0.545074 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2025-03-31 | "IC0010CEFE" | 1.0 | -1.285839 | -1.222433 | -0.329952 | -1.720335 | -0.308083 | -0.722759 | 0.065942 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2025-03-31 | "IC0021AFB7" | 1.0 | -0.051292 | 0.32115 | 0.089333 | -1.19551 | 1.170225 | 0.043881 | -0.063537 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2025-03-31 | "IC002CE8B9" | 1.0 | 0.182563 | 1.148245 | -0.346659 | 1.208164 | 0.840697 | 0.036426 | 0.270647 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2025-03-31 | "IC002DC646" | 1.0 | 0.243023 | 0.433831 | 0.404471 | -0.636615 | -0.351917 | 0.312706 | 0.092901 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 2026-03-31 | "ICFFE60191" | 1.0 | -0.273989 | -0.719099 | -0.455453 | 0.093599 | 0.41578 | -0.023262 | 0.792578 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2026-03-31 | "ICFFE938FD" | 1.0 | 0.937859 | 0.453033 | -1.984274 | -0.396667 | 0.218596 | 1.212203 | 0.890377 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 2026-03-31 | "ICFFE94AED" | 1.0 | 0.172092 | 0.888173 | 0.230857 | -1.064806 | 1.195682 | 1.02299 | 0.981633 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2026-03-31 | "ICFFEBBB38" | 1.0 | 0.594618 | 0.442887 | 0.610477 | -0.939575 | 0.750127 | 0.424111 | 0.202413 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2026-03-31 | "ICFFF2F5AD" | 1.0 | -0.719509 | -0.759684 | -2.317359 | 1.000015 | -0.129688 | -0.071235 | -1.38441 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
Lastly we create the new dataset followed by describing its properties after creation.
my_risk_dataset = risk_datasets.create_dataset(risk_dataset_name, settings)
Data Coverage#
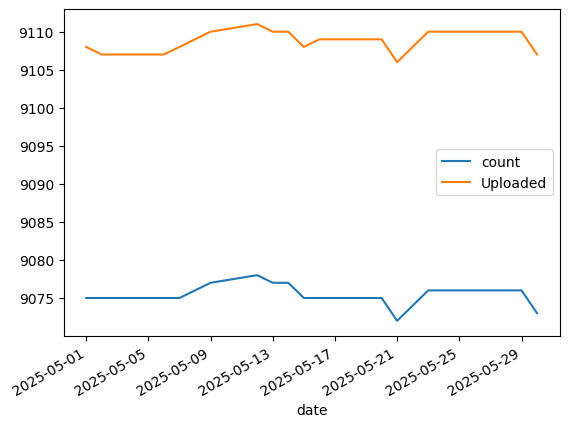
As a first step after the risk dataset creation we cross check the asset coverage compared to our raw exposure upload.
upload_stats_df = uploader.get_data_detail_summary()
upload_stats_df.head()
| date | n_assets | min_exposure | max_exposure | mean_exposure | std_exposure |
|---|---|---|---|---|---|
| date | i64 | f32 | f32 | f64 | f64 |
| 2025-05-01 | 9108 | -3.0 | 3.0 | 0.07378 | 0.871145 |
| 2025-05-02 | 9107 | -3.0 | 3.0 | 0.075814 | 0.869677 |
| 2025-05-03 | 9106 | -3.0 | 3.0 | 0.075695 | 0.869591 |
| 2025-05-04 | 9106 | -3.0 | 3.0 | 0.075698 | 0.869592 |
| 2025-05-05 | 9107 | -3.0 | 3.0 | 0.080996 | 0.868992 |
uploader.get_data().collect()
| date | asset_id | asset_id_type | factor_group | factor | exposure |
|---|---|---|---|---|---|
| date | str | str | str | str | f32 |
| 2025-05-29 | "ICAA2EFD35" | "bayesid" | "style" | "Dividend" | -0.183716 |
| 2025-05-29 | "ICAA3A3F2F" | "bayesid" | "style" | "Dividend" | -0.183716 |
| 2025-05-29 | "ICAA3BE3DD" | "bayesid" | "style" | "Dividend" | 0.151978 |
| 2025-05-29 | "ICAA3C9D8A" | "bayesid" | "style" | "Dividend" | 0.083496 |
| 2025-05-29 | "ICAA683694" | "bayesid" | "style" | "Dividend" | -0.183716 |
| … | … | … | … | … | … |
| 2025-05-31 | "IC95A06496" | "bayesid" | "style" | "Value" | -0.117798 |
| 2025-05-31 | "IC95AC841D" | "bayesid" | "style" | "Value" | 0.391357 |
| 2025-05-31 | "IC95AD394E" | "bayesid" | "style" | "Value" | 0.486816 |
| 2025-05-31 | "IC95AED504" | "bayesid" | "style" | "Value" | -1.547852 |
| 2025-05-31 | "IC95AEEB70" | "bayesid" | "style" | "Value" | 0.044647 |
# note that the industry and region hierarchy names tie out with the factor groups we specified above
print(f"Categorical Hierarchies {list(my_risk_dataset.describe().universe_settings_menu.categorical_hierarchies.keys())}")
Categorical Hierarchies ['trbc']
universe_settings = UniverseSettings()
universe_api = bln.equity.universes.load(
universe_settings.with_dataset(risk_dataset_name)
)
universe_counts = universe_api.counts()
(
universe_counts
.join(
upload_stats_df.select("date", "n_assets").rename({"n_assets": "Uploaded"}),
on="date",
how="left",
)
.sort("date")
.to_pandas()
.set_index("date")
.plot()
)
<Axes: xlabel='date'>
We can pull some exposures from the new risk dataset to verify.
exposures_api = bln.equity.exposures.load(
ExposureSettings(
exposures=[
ContinuousExposureGroupSettings(hierarchy="market"),
ContinuousExposureGroupSettings(hierarchy="style", standardize_method="equal_weighted"),
],
).with_dataset(risk_dataset_name)
)
df = exposures_api.get(universe_settings, standardize_universe=None)
df.tail()
| date | bayesid | market.Market | style.Dividend | style.Growth | style.Leverage | style.Momentum | style.Size | style.Value | style.Volatility |
|---|---|---|---|---|---|---|---|---|---|
| date | str | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 |
| 2025-05-31 | "ICFFE54368" | 1.0 | -0.844152 | -0.702781 | 0.094035 | -1.14596 | 0.962314 | -2.420384 | 0.370091 |
| 2025-05-31 | "ICFFE60191" | 1.0 | -0.107817 | -0.069119 | -0.164538 | 0.38831 | -0.501507 | 0.246586 | 0.64925 |
| 2025-05-31 | "ICFFE94AED" | 1.0 | 1.232723 | 0.386306 | 1.141383 | 0.702094 | 0.179885 | 1.009319 | -1.267412 |
| 2025-05-31 | "ICFFEBBB38" | 1.0 | 0.400454 | 0.678276 | 0.293858 | 0.704019 | 0.635378 | 0.376627 | -1.352522 |
| 2025-05-31 | "ICFFF2F5AD" | 1.0 | -0.116423 | -0.081757 | -0.172153 | -0.798808 | -0.521222 | 0.244388 | 0.196752 |